Descrição do Projeto
O projeto foi desenvolvido utilizando meus conhecimentos relacionados à infraestrutura de servidores Linux, banco de dados PostgreSQL, linguagem de programação Python e criação de dashboards utilizando PowerBI.
O objetivo deste projeto é utilizar a base de dados escolar do Governo (disponível no link abaixo) para que o usuário obtenha com facilidade as informações necessárias.
Censo Escolar - GovernoStorytelling
Ao final do projeto, o usuário será capaz de visualizar facilmente informações sobre o censo escolar dos anos 2021, 2022 e 2023, no cenário pós-pandemia, para analisar a quantidade de alunos, que fazem parte de minorias sociais e estavam matriculados em escolas privadas nos três turnos: Diurno, Noturno e EAD.
Passos
-
Análise Exploratória
No estágio inicial da análise, meu objetivo é verificar a estrutura inicial da base de dados e verificar quais campos são condizentes com o objetivo do projeto.
Ao baixar os arquivos no site do Governo notei que existem dois arquivos principais:
- Microdados: arquivo .CSV que contém os dados do censo;
- Dicionários: arquivo .XLSX que contém significado das siglas utilizadas nas colunas do arquivo .CSV.
O arquivo .CSV, referente ao ano de 2021, possuía 77.071 linhas e 370 colunas. Não é interessante manter a base extensa desse jeito, pois, além de eu já ter um objetivo muito claro, uma base extensa trará complexidade à criação do dashboard e, consequentemente, lento e pesado.
Mas, em contra partida, um arquivo extenso desse jeito, daria um certo trabalho para ser adaptado manualmente e, após ajustar o arquivo de 2021, ainda seria necessário ajustar os arquivos dos dois anos seguintes.
Por esse motivo, optei por utilzar o Python para automatizar esse processo.
-
Infraestrutura de Servidor Linux
Utilizei um servidor VPS que utiliza o sistema operacional Ubuntu, baseado em Linux, é gratuito e possui código aberto.
A configuração do servidor exigiu instalações de bibliotecas Python, banco de dados PostgreSQL, criação de scripts e conexão com o PowerBI.
- Estrutura
- ETL do arquivo .CSV:
PythonMinha ideia inicial é utilizar o Python para automatizar o processo de adaptar as bases de dados.
Para instalar o Python em meu servidor, utilizei o comando abaixo:
[root ~]# sudo apt install python3-pipO comando acima instala tanto o Pyhton 3, quanto o gerenciador de pacotes
pip.Segui também instalando uma biblioteca Python que será utilizada durante o desenvolvimento do script.
[root ~]# pip3 install sqlalchemyO próximo passo foi criar o script.
As bibliotecas utilizadas no script foram:
#!/usr/bin/env python3 import pandas as pd import subprocess import os import logging from sqlalchemy import create_engine, text from sqlalchemy.exc import ProgrammingErrorO script foi pensado para funcionar da seguinte forma:
ETL é o processo de transformação dos dados. A sigla significa Extract (extração), Transform (transformação) e Loading (carregamento).
O processo de extração se inicia solicitando a base de dados inicial e apresentando a informação da quantidade de colunas que o arquivo possui.
# Entrada do nome do arquivo CSV bruto arquivo_entrada = input("🔍 Qual é o nome do arquivo .csv A SER TRATADO (inclua .csv)? ") df = pd.read_csv(arquivo_entrada, sep=";", encoding="latin1", low_memory=False) print(f"\n📊 Colunas antes do tratamento: {df.shape[1]}")O processo de transformação dos dados altera o nome das colunas inicias, que estão em sigla, e ajusta para o nome real da coluna, conforme informado no arquivo .XLSX disponibilizado pelo Governo.
As colunas tem seus nomes alterados através de um dicionário python.
Ainda nessa etapa, optei por apresentar no script a informação da quantidade de linhas que possuiam dados nulos, o nome das colunas, após a alteração, e a quantidade de colunas final, já que as demais colunas não serão utilizadas e foram removidas.
Importante sinalizar de que nessa etapa, e nas próximas, existem códigos criados para tratamento de erros.
# Lista de colunas que queremos manter colunas_desejadas = [ 'NU_ANO_CENSO', 'NO_REGIAO', 'NO_UF', 'SG_UF', 'NO_MUNICIPIO', 'IN_MANT_ESCOLA_PRIVADA_EMP', 'IN_MANT_ESCOLA_PRIVADA_ONG', 'IN_MANT_ESCOLA_PRIVADA_OSCIP', 'IN_MANT_ESCOLA_PRIV_ONG_OSCIP', 'IN_MANT_ESCOLA_PRIVADA_SIND', 'IN_MANT_ESCOLA_PRIVADA_SIST_S', 'IN_MANT_ESCOLA_PRIVADA_S_FINS', 'QT_MAT_MED', 'QT_MAT_BAS_FEM', 'QT_MAT_BAS_MASC', 'QT_MAT_BAS_PRETA', 'QT_MAT_BAS_PARDA', 'QT_MAT_BAS_INDIGENA', 'QT_MAT_BAS_15_17', 'QT_MAT_BAS_D', 'QT_MAT_BAS_N', 'QT_MAT_BAS_EAD', 'QT_DOC_MED', 'QT_TUR_MED' ] # Filtrar as colunas desejadas e remover nulos df = df[colunas_desejadas] df.dropna(inplace=True) print(f"📌 Existem {df.isnull().sum().sum()} dados nulos no DataFrame.") # Dicionário de renomeação colunas_renomear = { 'NU_ANO_CENSO': 'ano_do_censo', 'NO_REGIAO': 'regiao_geografica', 'NO_UF': 'uf', 'SG_UF': 'sigla_uf', 'NO_MUNICIPIO': 'municipio', 'IN_MANT_ESCOLA_PRIVADA_EMP': 'escola_privada_empresa', 'IN_MANT_ESCOLA_PRIVADA_ONG': 'escola_privada_ong', 'IN_MANT_ESCOLA_PRIVADA_OSCIP': 'escola_privada_oscip', 'IN_MANT_ESCOLA_PRIV_ONG_OSCIP': 'escola_privada_ong_oscip', 'IN_MANT_ESCOLA_PRIVADA_SIND': 'escola_privada_sindicato', 'IN_MANT_ESCOLA_PRIVADA_SIST_S': 'escola_privada_sistema_s', 'IN_MANT_ESCOLA_PRIVADA_S_FINS': 'escola_privada_sf', 'QT_MAT_MED': 'qtd_matriculas_em', 'QT_MAT_BAS_FEM': 'qtd_matriculas_fem', 'QT_MAT_BAS_MASC': 'qtd_matriculas_masc', 'QT_MAT_BAS_PRETA': 'qtd_matriculas_preta', 'QT_MAT_BAS_PARDA': 'qtd_matriculas_parda', 'QT_MAT_BAS_INDIGENA': 'qtd_matriculas_indigena', 'QT_MAT_BAS_15_17': 'qtd_matriculas_15_17', 'QT_MAT_BAS_D': 'qtd_matriculas_diurno', 'QT_MAT_BAS_N': 'qtd_matriculas_noturno', 'QT_MAT_BAS_EAD': 'qtd_matriculas_ead', 'QT_DOC_MED': 'qtd_docentes_em', 'QT_TUR_MED': 'qtd_turmas_em' } # 🔄 Renomear as colunas com segurança df.rename(columns=colunas_renomear, inplace=True) # ✅ Verificar se a renomeação foi realizada com sucesso print("\n📋 Nomes das colunas após renomeação:\n") for i, coluna in enumerate(df.columns): print(f"{i+1:02d}. {coluna}") # 🔍 Conferência das colunas que deveriam ter sido renomeadas colunas_nao_renomeadas = [col for col in colunas_renomear if col in df.columns] if colunas_nao_renomeadas: print("\n⚠️ Atenção! As seguintes colunas não foram renomeadas:") for col in colunas_nao_renomeadas: print(f" - {col}") else: print("\n✅ Todas as colunas foram renomeadas com sucesso!") print(f"\n🔢 Total de colunas após renomeação: {len(df.columns)}")E, por fim, entramos na etapa final, o carregamento dos dados.
O script solicita um nome para a base de dados e tabela que serão criados e, então, uma string é responsável por realizar a conexão com o PostgreSQL.
Importante sinalizar, o código responsável pelo tratamento de erros e checagem de duplicidade de banco de dados e tabela. Caso a informação adicionada já exista, a criação não é finalizada, porém o dados serão adicionados na base já existente.
# 💾 Entrada do nome do arquivo tratado arquivo_saida = input("\n💾 Qual será o nome do ARQUIVO TRATADO (.csv)? ") df.to_csv(arquivo_saida, sep=";", index=False) #Solicita ao usuário o nome do Banco de Dados BANCO_DESTINO = input("Digite o nome do banco de dados a ser criado: ") #Solicita ao Usuário o nome da Tabela TABELA = input("Digite o nome do Tabela a ser criada: ") #vai ser o arquivo_saida # String de conexão com o banco postgres padrão conn_string = f"postgresql+psycopg2://{USUARIO}:{SENHA}@{HOST}:{PORTA}/postgres" # ========== CRIAÇÃO DO BANCO DE DADOS COM VERIFICAÇÃO DE DUPLICIDADE ========== try: #engine = create_engine(conn_string) engine = create_engine(conn_string, isolation_level="AUTOCOMMIT") with engine.connect() as conn: # Verifica se o banco já existe resultado = conn.execute( text("SELECT 1 FROM pg_database WHERE datname = :nome"), {"nome": BANCO_DESTINO} ).fetchone() if resultado: msg = f"Banco de dados '{BANCO_DESTINO}' já existe. Nenhuma ação tomada." print(msg) logging.info(msg) else: # Criação do banco conn.execute(text(f"CREATE DATABASE {BANCO_DESTINO}")) msg = f"Banco de dados '{BANCO_DESTINO}' criado com sucesso!" print(msg) logging.info(msg) except ProgrammingError as e: logging.error(f"Erro de programação ao criar banco: {e}") print("Erro ao criar banco de dados.") except Exception as e: logging.error(f"Erro inesperado: {e}") print("Erro inesperado. Verifique o log.") # Conecta no novo banco e cria a tabela com base no CSV engine = create_engine(f"postgresql+psycopg2://{USUARIO}:{SENHA}@{HOST}:{PORTA}/{BANCO_DESTINO}") df.to_sql(TABELA, engine, if_exists="replace", index=False) print(f"Tabela '{TABELA}' criada com sucesso no banco '{BANCO_DESTINO}' com base no CSV.") # (Opcional) Dump do banco em .pgsql os.environ["PGPASSWORD"] = SENHA arquivo_dump = f"{BANCO_DESTINO}.pgsql" subprocess.run([ "pg_dump", "-h", HOST, "-U", USUARIO, "-d", BANCO_DESTINO, "-f", arquivo_dump ], check=True) print(f"Arquivo de backup '{arquivo_dump}' gerado com sucesso.")Ainda sobre o banco de dados, foi criado um bloco de códigos na intenção de, caso apresentar erro na criação da base de dados ou tabela, o erro ser armazenado em um arquivo de log para facilitar o entendimento do erro.
# ========== CONFIGURAÇÃO DO LOG (Auditoria) ========== logging.basicConfig( filename='auditoria_banco.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s' )Abaixo vou deixar alguns dos erros armazenados no arquivo de log durante a implementação/execução do script.
2025-04-09 13:40:54,232 - ERROR - Erro inesperado: (psycopg2.OperationalError) connection to server at "localhost" (::1), port 5432 failed: FATAL: password authentication failed for user "postgres" (Background on this error at: https://sqlalche.me/e/20/e3q8) 2025-04-09 14:06:05,262 - ERROR - Erro inesperado: (psycopg2.errors.ActiveSqlTransaction) CREATE DATABASE cannot run inside a transaction block [SQL: CREATE DATABASE banco_de_teste_v1] (Background on this error at: https://sqlalche.me/e/20/2j85) 2025-04-09 14:08:09,294 - INFO - Banco de dados 'banco_de_teste_v1' criado com sucesso! 2025-04-09 14:24:21,636 - INFO - Banco de dados 'banco_teste_v2' criado com sucesso! 2025-04-09 14:45:14,125 - ERROR - Erro de programação ao criar banco: (psycopg2.errors.SyntaxError) syntax error at or near "-" LINE 1: CREATE DATABASE teste-banco-v3A parte final do script, ainda na etapa de carregamento, também permite que a base de dados seja adicionada ao GitHub. Dessa forma, caso alguma outra pessoa precisasse baixar a base de dados em outro ambiente, seria rapidamente realizado ou através de alguma script, ou até mesmo com algum comando git em um servidor.
O script aplica um commit para adicionar arquivos em um repositório no GitHub.
Para realizar a configuração inicial, foi necessário configurar uma Key para conectar o GitHub com servidor.
O script também possui tratamento de erros, muito importante para interpretar mais facilmente o motivo do erro.
# 📤 Envio para o GitHub if os.path.exists(arquivo_saida): try: print("\n🚀 Enviando arquivo para o GitHub...") # Adiciona o arquivo ao stage subprocess.run(["git", "add", arquivo_saida], check=True) subprocess.run(["git", "add", arquivo_dump], check=True) # Faz o commit com mensagem mensagem_commit = ( "🚀 Adicionando arquivos gerados:\n" f"- CSV tratado: {arquivo_saida}\n" f"- Dump PostgreSQL: {arquivo_dump}" ) subprocess.run(["git", "commit", "-m", mensagem_commit], check=True) # Envia para o repositório subprocess.run(["git", "push", "origin", "master"], check=True) print("🎉 Upload para o GitHub concluído com sucesso!") except subprocess.CalledProcessError as e: print(f"❌ Ocorreu um erro durante o envio ao GitHub: {e}") else: print("⚠️ Arquivo de saída não encontrado. Nada foi enviado ao GitHub.") print(f"\n✅ ETL finalizado com sucesso! Arquivo salvo como: {arquivo_saida}")Verifique no vídeo abaixo o funcionamento do script.
PostgreSQLAs bases de dados do Governo, serão aramazenadas em um banco de dados PostgreSQL. A versão escolhida foi a 15.12.
[root ~]# sudo apt install postgresql-15Para validar a versão instalada utlizei o comando abaixo:
[root ~]# psql --version psql (PostgreSQL) 15.12A instalação do PostgreSQL funciona como uma nova instância dentro do servidor para acessar é necessário utilizar o seguinte comando:
psql -U [usuário]ou
sudo -u [usu[ario] psqlAo acessar é possível verificar a mudança da instância de
[root ~]#parapostgres=#.O comando
\listé responsável por listar todos os bancos de dados criados no servidor:postgres=# \list Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges -------------------------+----------+----------+-------------+-------------+------------+-----------------+----------------------- banco_censo | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | banco_de_teste_v1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | banco_teste_v2 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | banco_teste_v5 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | banco_teste_v6 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | banco_treinamento | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | banco_treinamento_teste | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | banco_treinamentos_teste | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | =c/postgres + | | | | | | | postgres=CTc/postgres teste_banco_v4 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | testemartinha | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | libc | (13 rows)O comando
\cé responsável por acessar uma base de dados:postgres=# \c banco_censo You are now connected to database "banco_censo" as user "postgres". banco_censo=#O comando
\dtlista as tabelas dentro da base de dados.banco_censo=# \dt List of relations Schema | Name | Type | Owner --------+-----------+-------+---------- public | censo2021 | table | postgres public | censo2022 | table | postgres public | censo2023 | table | postgres (3 rows)O comando
\dlista as colunas dentro da tabela da base de dados.banco_censo=# \d censo2021 Table "public.censo2021" Column | Type | Collation | Nullable | Default --------------------------+--------+-----------+----------+--------- ano_do_censo | bigint | | | regiao_geografica | text | | | uf | text | | | sigla_uf | text | | | municipio | text | | | escola_privada_empresa | bigint | | | escola_privada_ong | bigint | | | escola_privada_oscip | bigint | | | escola_privada_ong_oscip | bigint | | | escola_privada_sindicato | bigint | | | escola_privada_sistema_s | bigint | | | escola_privada_sf | bigint | | | qtd_matriculas_em | bigint | | | qtd_matriculas_fem | bigint | | | qtd_matriculas_masc | bigint | | | qtd_matriculas_preta | bigint | | | qtd_matriculas_parda | bigint | | | qtd_matriculas_indigena | bigint | | | qtd_matriculas_15_17 | bigint | | | qtd_matriculas_diurno | bigint | | | qtd_matriculas_noturno | bigint | | | qtd_matriculas_ead | bigint | | | qtd_docentes_em | bigint | | | qtd_turmas_em | bigint | | |Verifique no vídeo abaixo o funcionamento da instância do banco de dados.
-
Dashboard
Para a criação do Dashboard, o design foi criado utilizando o Figma.
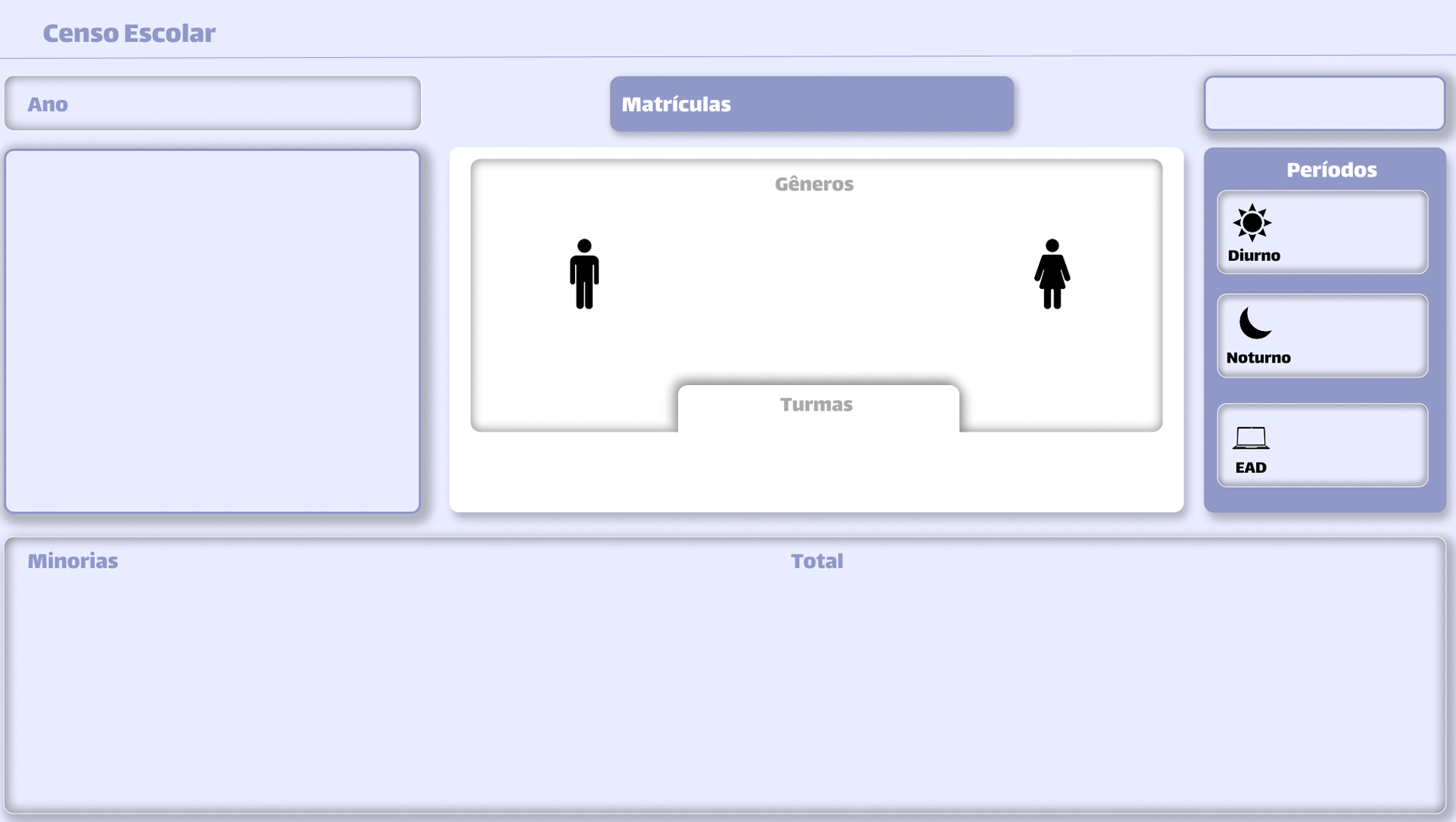
O dashboard será estruturado da seguinte forma:
- Filtros
- Métricas
No dashboard será possível filtrar baseado em duas classes: Localização e Ano.
Ambos estão localizados no canto superior esquerdo do dashboard.
O dasboard apresenta as métricas nos campos de matrícula, gêneros, turmas, minorias e períodos.
PowerBI
Como o banco de dados está em um servidor, é necessário conectar o PowerBI com o servidor do banco.
A conexão foi realizada utilizando o conector ODBC do PowerBI com a String de Conexão:
Driver={PostgreSQL Unicode}; Server={IP}; Port=5432; Database=banco_censo;
Conforme explicado anteriormente, o objetivo desse projeto é analisar a evolução ou regressão de indicadores e o cenário pós pandemia, focando em escolas privadas, no ensino médio e matrículas de minorias.
Logo abaixo, você pode verificar o projeto em seu estágio final.
Durante a criação deste projeto, obtive valiosos conhecimentos na área de infraestrutura de servidor, desenvolvimento de script em Python, banco de dados PostgreSQL, e desenvolvimento do dashboard com o PowerBI.
Muito obrigada por ter acompanhado até aqui!
Suzana Cavalcante.